第3回 顔画像の感情認識
今回のテーマは顔画像の感情認識です。顔画像の感情認識は画像系のタスクで、前回の一般物体認識に近いですが、検出対象を人間の顔のみとし、検出した領域に対して感情認識を行うという点が一般物体認識とは異なります。顔画像の感情認識の概要については解説動画をご覧ください。
今回の実装のソースコードはこちらからダウンロードできます。
目次
解説動画
ハンズオン概要
目的
本ハンズオンはクラウドAPIや、学習済みモデルを利用し、感情認識を行う簡単なアプリケーションを実装することで、AI技術を体感することが目的となっています。クラウドサービスを利用するため、いくつかのアカウントは必要となりますが、ブラウザで実装できるため、環境構築は不要です。
使用するクラウドAPI
ここではMicrosoft AzureのCognitive services Face APIという顔認識用のクラウドAPIを使用します。このFace APIに画像をアップロードすることで、
- 顔のバウンディングボックス(認識対象を囲む四角形)
- 感情
- 見た目の年齢
- 性別
といった認識結果を表示してくれます。今回はバウンディングボックスと感情の認識結果を取得します。
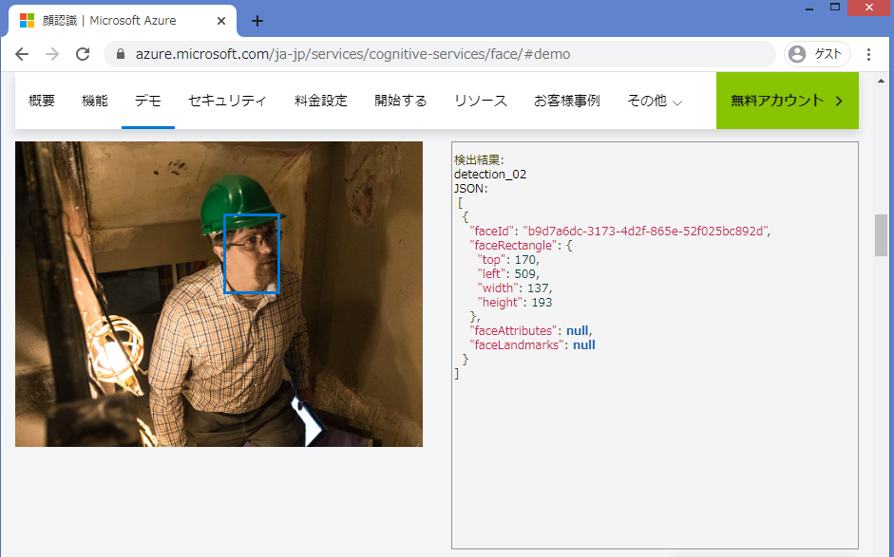
より詳細な使用方法が知りたい方はAPIリファレンスがありますのでこちらをご参照ください。
準備
前回同様、以下のサービスのアカウントが必要になります。持っていない場合は事前に作成しておいてください。どちらも無料で作成できます。
Face APIのリソース作成
API呼び出しを行うためには呼び出す対象となるリソースを作成する必要があります。Face APIのリソースは以下のリンクから作成できます。リソースを作成すると、エンドポイントURLとAPIキーが作成されます。これらはAPI呼び出し時に必要となるので、用意しておいてください。
https://portal.azure.com/#create/Microsoft.CognitiveServicesFace
※リソースの作成方法について
Google Colaboratory
前回と同様、Google Colaboratoryを使用します。Google Colaboratoryに関する説明はこちら
使用する画像の用意
画像は以下の画像を使用します。他の好きな画像を使用しても構いません。

実装
画像読み込み
curlで使用する画像をURLから取得し、sample.jpgという名前でColaboratory上にアップロードします。(Colaboratoryでは!(エクスクラメーションマーク)を先頭に付けることでLinuxコマンドが実行できます)
!curl https://publicdomainq.net/images/201703/28s/publicdomainq-0007399cke.jpg > sample.jpg※ローカルPCからアップロードする方法はこちら
アップロードした画像をPythonで読み込み、画面に表示します。
# ライブラリのインポート
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
# ファイル名をセット
filename = '/content/sample.jpg'
# Pillowライブラリで画像を表示
img = Image.open(filename)
img = img.resize((900, 600))
img.save(filename)
plt.imshow(img)
plt.show()
API呼び出し
Azureの感情認識API「Face API」を呼び出し、感情認識の結果を取得します。
以下のコードではPythonのサードパーティパッケージRequestsを用いてHTTPのPOSTメソッドによるAPI呼び出しを行っています。(Google ColaboratoryにはRequestsパッケージがプレインストールされているのでインストールは不要です。)
リクエストのURLは以下のように設定します。{endpoint}に作成したAzureのエンドポイントを入れてください。
https://{endpoint}/face/v1.0/detect
例:エンドポイントがhogehoge.azure.comの場合、「https://hogehoge.azure.com/face/v1.0/detect」とする
import requests
# Azure_URL
analyze_url = 'https:/{endpoint}/face/v1.0/detect' # {endpoint}に作成したAzureのエンドポイントを入力してください
# Azure_キー
subscription_key = 'XXX' # エンドポイント作成時に発行したキーを入力してください
# http通信の設定
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Content-type':'application/octet-stream'
}
# リクエストパラメータの設定
params = {
'returnFaceId': 'true',
'returnFaceLandmarks': 'false',
'returnFaceAttributes': 'emotion', # 感情の認識結果を返すように設定
'recognitionModel': 'recognition_04',
}
# バイナリ形式で画像読み込み
with open(filename, 'rb') as f:
binary = f.read()
# HTTP通信実行
response = requests.post(analyze_url, headers=headers, params=params, data=binary)
# リクエスト結果の確認
print(response)<Response [200]>
<Response [200]>(通信成功)と表示されればOKです。
データ整形
リクエスト結果の中身を確認するため、response.json() を実行してみます。
# レスポンスの確認
response.json()[{'faceAttributes': {'emotion': {'anger': 0.0, 'contempt': 0.016, 'disgust': 0.0, 'fear': 0.0, 'happiness': 0.784, 'neutral': 0.199, 'sadness': 0.0, 'surprise': 0.0}}, 'faceId': '45ab7cb9-9a85-477e-ac73-086581d54c46', 'faceRectangle': {'height': 105, 'left': 367, 'top': 120, 'width': 105}}]
response.json()の出力はAzure Face APIが認識した結果をJSON形式で表したものとなっています。このままでは読みにくいのでPandasのDataFrame形式に変換します。
import pandas as pd
# 表を作成
columns = [
'anger',
'contempt',
'disgust',
'fear',
'happiness',
'neutral',
'sadness',
'surprise',
'top',
'height',
'left',
'width'
]
df = pd.DataFrame(columns=columns)
# 通信の結果からバウンディングボックスの情報を取得
faces = response.json()
# 認識した顔ごとにループ
for face in faces:
# 要素抽出(感情)
emotions = face['faceAttributes']['emotion']
anger = emotions['anger']
contempt = emotions['contempt']
disgust = emotions['disgust']
fear = emotions['fear']
happiness = emotions['happiness']
neutral = emotions['neutral']
sadness = emotions['sadness']
surprise = emotions['surprise']
# 要素抽出(バウンディングボックス)
rectangle = face['faceRectangle']
top = rectangle['top']
height = rectangle['height']
left = rectangle['left']
width = rectangle['width']
# 表に追加
tmp_se = pd.Series([anger,
contempt,
disgust,
fear,
happiness,
neutral,
sadness,
surprise,
top,
height,
left,
width],
index=columns)
df = df.append(tmp_se, ignore_index=True)# 表を表示
df| anger | contempt | disgust | fear | happiness | neutral | sadness | surprise | top | height | left | width | |
| 0 | 0 | 0.016 | 0 | 0 | 0.784 | 0.199 | 0 | 0 | 120 | 105 | 367 | 105 |
画像に対してAIが検出した矩形領域のことをバウンディングボックスといいますが(今回の場合は顔画像の検出された領域)、この表のtop, height, left, widthはそれぞれ検出されたバウンディングボックスの上端位置、高さ、左端位置、幅を表します。
それ以外のカラムは検出されたバウンディングボックス内の感情の割合を表します。各感情の説明は以下の通りです。
| 感情 | 説明 |
|---|---|
| anger | 怒り |
| contempt | 軽蔑 |
| disgust | 嫌悪 |
| fear | 恐怖 |
| happiness | 幸福 |
| neutral | 中性 |
| sadness | 悲しみ |
| surprise | 驚き |
先ほどの結果を見ると、検出された顔画像に対して、happiness(幸福)の感情が0.784と最も高く認識されたことが分かります。
画像書き込み・グラフの表示
では実際に認識された顔の部分をバウンディングボックスで囲んで表示してみます。
from PIL import ImageDraw
import copy
# 画像のコピーを作成
copy_img = copy.deepcopy(img)
draw = ImageDraw.Draw(copy_img)
# バウンディングボックス書き込み
color = 'red'
for _, row in df.iterrows():
xy = (row['left'],
row['top'],
row['left'] + row['width'],
row['top'] + row['height'])
draw.rectangle(xy, outline=color)
# 画面表示
plt.imshow(copy_img)
plt.show()
次に認識された感情の割合を円グラフに表します。
# 感情を円グラフで表示
label = ['anger','contempt','disgust','fear','happiness','neutral','sadness','surprise']
x = [df.loc[0, emotion] for emotion in label]
plt.pie(x, labels=label)
plt.show()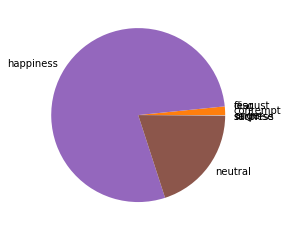
演習問題
インターネットから画像データを探して、APIを使って解析してみてください。
今回はこれで以上になります。次回のテーマは犬猫画像分類です。画像分類に用いる畳み込みニューラルネットワークの解説と、事前学習済みのニューラルネットワークモデルVGG16を用いた犬と猫の画像分類を行う予定です。
最後までお読みいただきありがとうございました。それでは引き続き次回もよろしくお願いいたします。

